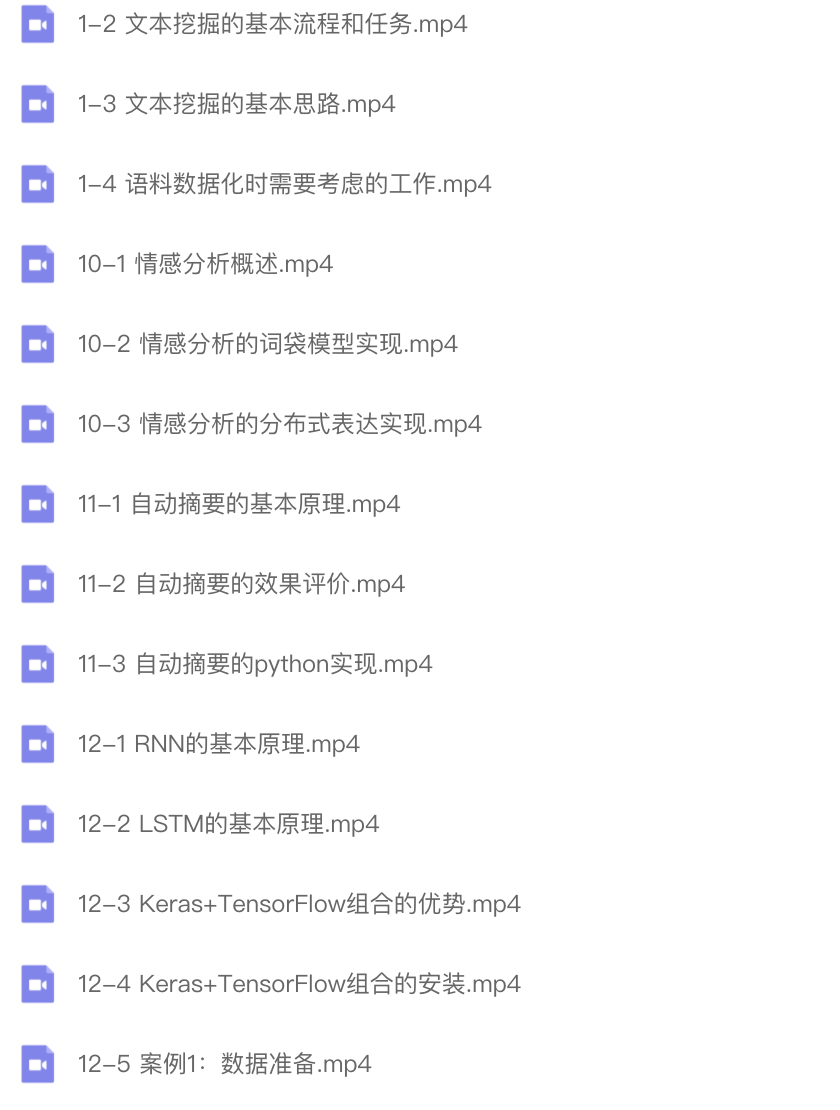
从基本的分词、词袋模型、分布式表示等概念开始,多面深入学习文本挖掘技术的各个方面。
文本挖掘(TM),又称自然语言处理(NLP),是AI时代炙手可热的数据分析挖掘前沿领域,其所涉及的人机对话系统,推荐算法,文本分类等技术在BAT等企业中都得到广泛应用。
本课程将使用经典武侠小说、大众点评抓取结果、微博语料数据等多个实际案例进行教学。
本次课程将会从基本的分词、词袋模型、分布式表示等概念开始,多面介绍文本挖掘技术的各个方面,特别会针对目前最热的word2vec,gensim 等结合实际案例进行学习,帮助学员直接升级至业界技术前沿。
学习完本课程后,学员将能够独立使用Python环境完成中文文本挖掘的各种工作。
声明:吾爱学堂是一个资源分享和技术交流平台,本站所发布的一切破解补丁、注册机和注册信息及软件的解密分析文章仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。本站信息来自网络,版权争议与本站无关。您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容。如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。